Az Arteries csapatánál folyamatosan teszteljük és vizsgáljuk, hogy milyen konkrét gyakorlati alkalmazásai lehetnek a mai AI technológiáknak, amiket már ma be tudunk építeni applikációinkba, az általunk fejlesztett webes rendszerekbe. Ebben a cikksorozatban áttekintjük, hogy mely területeken segíthetünk ügyfeleinknek növelni üzleti folyamataik hatékonyságát, javítani termelékenységüket, vagy csökkenteni költségeiket az AI-al, de itt az első részben engedjetek meg nekünk néhány alapozó, ismeretterjesztő bekezdést is. Főzzetek le egy kávét, és kezdjük ezekkel! 😉
A gépi tanulás, mesterséges intelligencia alterülete rendkívüli fejlődésen ment át az elmúlt években. Ezt főleg a nagy, jó minőségű, annotált adatok, gyorsító hardverek adta számítási kapacitás és új, okosabb algoritmusok és eljárások tették lehetővé.
Neurális hálózatok:
Minden mai, state of the art gépi tanulásos (“AI”) program kizárólag mesterséges neurális hálózatra épít, ahol idegsejtek súlyozott módon kapcsolódnak össze egymással, rétegenként, különböző architektúrában. A neuronok (idegek) képesek más neuronok eredményeire is építeni, majd így tovább, hasonlóan a biológiai agyhoz. A matematikai megfogalmazás szerint a neurális hálózat egy “univerzális függvény approximátor”, ami azt jelenti, hogy sok bemenet-kimenet, vagy hatás-reakció adat pár ismeretében képes azzá a szabállyá (függvénnyé) válni, ami a kimenetet eredményezte a bemenet “függvényében”. Mivel a valóságban mindent számszerűsíthető függvények vezérelnek, a fizika törvényeitől kezdve a társadalom működéséig, ezért a neurális hálózatok elméletileg mindenre képessé tehetők. A gyakorlatban a használhatóságukat persze limitálja a háló mérete, felépítése (architektúrája) és az hogy, a tanításhoz használt adatok minőségéből és mennyiségéből mennyire jól lehet következtetni és általánosítani az őket generáló szabály(ok)ra.
Nézzünk egy egyszerű példát: a neurális hálózatok működése hasonló ahhoz, mint amikor egy gyerek biciklizni tanul. Kezdetben sok hiba és esés követi egymást, de idővel az agy ‘beállítja’ magát a helyes mozgásra, és a biciklizés automatikussá válik.
Tanítás:
A tanítási folyamat alatt egy pontosan számszerűsíthető teljesítmény mutató alapján, iteratívan, több ezerszer úgy módosítjuk a háló belső struktúráját, hogy kis lépésekben haladván, de egyre jobban teljesítsen az adott feladatra, ami lehet bármi. Többnyire ismert adatokat reprodukáltatunk vele, hogy új, eddig sosem látott bemenetek esetén is meg tudja mondani a várható kimenetet. Ez a kimenet lehet pl: kategorizálás, döntés, előrejelzés, idősor, kép, hang, szöveg vagy bármi, amit csak számszerűsíteni lehet. Ez a felügyelt tanulás, vagyis Supervised learning elve, ami a ma leginkább elterjedt módszer. A tanulás másik formája a felügyelet nélküli (unsupervised learning), ahol még kevesebb adat van a tanulandó szabályról. Itt csakis a hatékonyság mérésre támaszkodhat a háló, pl: egy önvezető autó mennyire gyorsan ér a célhoz, károkozás és szabályszegés nélkül.
A világ talán legalapvetőbb elve a “legkisebb hatás elve”: eszerint a lehetséges kimenetek közül az fog bekövetkezni, amelyik a legkisebb “energiapazarlással” jár. Ez az elv a mesterséges neurális hálózatok tanítására is igaz: a háló abba a struktúrába fog konvergálni amelyik a legkisebb munkával, a legegyszerűbb módon adja vissza a megtanulandó adatokat. Ha túl nagy a háló mérete (így a potenciálisan a kognitív képessége), vagy kevés adatból tud tanulni, akkor egyszerűen csak “bemagolja” őket, mert az a legegyszerűbb út. Ekkor persze nagyon jó pontokat ér el a betanított példákra, de új adatok esetén teljesen rossz eredményekre jut, ami használhatatlanná teszi valós feladatokra. A gyakorlatban sosem a tanításhoz használt adatokon validáljuk a valós pontosságát, hanem új, eddig sosem látott példákon teszteljük le, így biztosítva a jó generalizációt (overfitting megelőzés). A tanítás és háló paraméterek megválasztása folyamán olyan megszorításokat kell alkalmaznunk, hogy a hálónak ne maradhasson más választása, csak az hogy tényleg megértse az adatokban mélyen rejlő szabályokat. Ezen háló és tanítási paraméterek (pl: learning rate, neuronok és kapcsolataik (weight) száma, egymás mögé halmozott és az előző neuronok kimenetét tovább feldolgozó “rétegek” száma) optimális megválasztása a mai napig nem automatizált és nagy fejlesztői körültekintést igényel, mert a tanítás roppant erőforrás, így költség és időigényes! A tanítás után a háló már nem tanul. Úgy tekinthetünk rá, mint egy használatonkénti, kvázi időhurokban lévő, befagyott agy. Az egyszeri használata, vagyis új bemeneti adatokból történő kimenet számítás (inference) már sok nagyságrenddel kevesebb erőforrás igénnyel jár mint a tanítás!
Képzeljük el a tanítási folyamatot egy iskolai tanuláshoz hasonlóan. Ahogyan egy diák ismétli és gyakorolja az anyagot, úgy a neurális hálózat is “gyakorol”, amíg el nem éri a kívánt teljesítményt. Ezt egy ábra is szemléltetheti, ahol a tanulási iterációk száma és a teljesítmény közötti kapcsolatot ábrázoljuk.
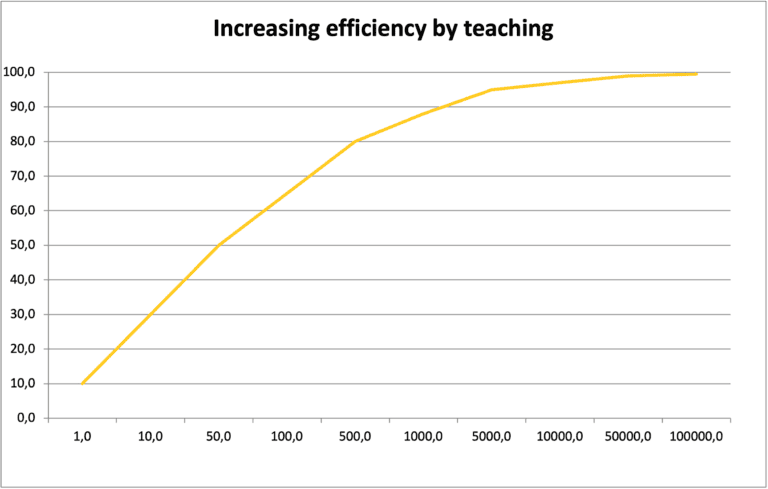
A százalékos pontosság és a training iterációk száma többnyire logaritmikusan viszonyulnak egymáshoz. Ez azt jelenti, hogy nagyon gyorsan, nagyon impresszív eredményeket érhetünk el, de egy pont fölött a számszerű pontosság már csak inkrementálisan, fokozatosan lassulva nő, így nagyon nehéz előre jelezni, vagy megbecsülni egy AI modell fejlődését! A tanítás elején, a felfutó ágban, naivan úgy tűnhet, hogy szinte pillanatokon belül teljesen megoldja a feladatot a neurális háló, ami könnyen, túlzottan optimista becsléshez vezethet! Azt is gondolhatjuk, hogy hamarosan elérünk egy optimum pontot, ahol maximális a hatékonyság/ráfordított erőforrás arány és onnantól már csak csökkenő hozadékkal tanítható tovább, de ez nem egészen van így!
Egy önvezető autó példájával: ha másodpercenként 1 döntést kell hoznia 99% vezetési pontosság mellett, akkor ~1 perc (69 sec) alatt okoz balesetet 50% os valószínűséggel! Egy 99.9% os önvezető AI-nál ez már ~10 percre (690 sec) nő, míg egy 99.99% os pontosságú autó ~2 óra alatt (6900 sec) szenved valószínűleg balesetet! A pontosság változás ugyan inkrementális, de a valódi hatásuk nagyon is számít! Ugyan ez a logika igaz egy tartalom szűrő, vagy minőségbiztosító AI-ra is! Nagyon fontos, hogy megfelelő, statisztikai szemmel vizsgáljuk meg a hatékonyságuk és valódi alkalmazási lehetőségeiket!
Az információs kor:
Az 21. század az információ kora, amely a tudás korszakának előfutára. Az emberiség történelme alatt nagyon sok adat és tudás halmozódott fel minden témakörben, ezek feldolgozásának legjobb módja pedig a gépi tanulás. Mivel a tanulandó adatokat többnyire emberek hozták létre vagy befolyásolták, intelligens, többnyire logikus folyamatok eredményeképpen, ezért az adatok reprodukciójához a neurális hálózat kénytelen maga is megtanulni és alkalmazni ezen logikus, intelligens folyamatokat!
Végső soron az intelligencia a megfigyelt hatás – effektek megfigyelését, hatásmechanizmusuk logikus, ok-okozati megértését és későbbi, célszerűen alkalmazott felhasználását jelenti. Az így szerzett megértés később felhasználható új, bonyolultabb folyamatok megértéséhez, majd így tovább (ez a rétegződés az emberi intelligencia egyik fő erőssége).
Elég nagy és sok rétegű (mély) hálóval, hatalmas, diverz adatmennyiség esetén, hosszan tanítva a mesterséges neurális hálózatok is képessé válnak az intelligencia folyamataira.
A valóság megértésének leghatékonyabb módja a logika, racionalitás és intelligencia, így ha egy neurális hálónak sok valós adatot kell megértenie, akkor a legegyszerűbb (és végső soron egyetlen) módja, hogy önmaga is ezen elvek alapján működjön és bizonyos mértékben intelligenssé váljon! Ekkor beszélhetünk igazán csak mesterséges intelligenciáról.
Az emergencia jelensége alapján egyszerűbb komponensek (atomok, vagy ezen esetben virtuális neuronok) összekapcsolódásából olyan új struktúra alakulhat ki, amely sokkal többre képes mint a komponensei önmagában. Az intelligencia is egy ilyen, komplex jelenség.
Az eszközhasználat és a technológia amely ezeket lehetővé tette és fejlesztette olyan mértékben megnövelte az emberiség képességeit, hogy a bolygó uralkodó fajává váltunk és elképzelhetetlennek vélt dolgokat tett mindennapossá. Viszont, nem az így kreált eszközök a legfontosabbak, vagy leghatalmasabbak, hanem az az intelligencia ami megalkotta őket! Ezen intelligencia, eszközszerű formába történő átvitele, korlátozásainak feloldása és automatizálása talán az emberiség legnagyobb és egyben utolsó szükséges műve.
Az emberi agy és a mesterséges intelligencia közötti párhuzam érdekes és tanulságos. Ahogyan az emberi agy is képes tanulni és alkalmazkodni, úgy a mesterséges intelligencia is képes új információk befogadására és alkalmazására.
A mai AI:
A mostani AI-ok többnyire kicsik, célfeladatokra specializáltak és az intelligencia definíciójának alsó határán mozognak (képfelismerés, besorolás, osztályozás, stb.), de már léteznek széleskörű képességeket mutató, nagyon értelmes, az univerzális mesterséges intelligencia (AGI) határát súroló fejlesztések. Ezek többnyire nagy nyelvi modellek (LLM), amik lényege, hogy emberek alkotta szöveg következő, kvázi “szótagját” (token-ét) jósolják meg. Ezen feladat magas szintű megoldása szinte lehetetlen intelligencia nélkül, valamint kvázi kifogyhatatlan (bemagolhatatlan) univerzális forrásanyag áll rendelkezésre a tanításhoz. A szavak értelmezése és egymással való kapcsolataik, a velük röviden definiált valós koncepciók szintén elősegítik a későbbi tudás építést és rétegződést. Ahogy a beszéd segítette az embert intelligenssé válni, úgy segítette az AI-t is. Ezek eredménye, hogy a GPT nyelvi modellek és társai olyan gyakorlati intelligenciával és képességekkel rendelkeznek, amely már az emberek egy jelentős részét felülmúlják!
Az AI használata:
Elméletileg ugyan minden feladatra alkalmazható a gépi tanulás, a gyakorlatban viszont limitált adatmennyiség és számítási kapacitás áll csak rendelkezésre. Az egyszerű, tradicionális, algoritmikus programokat nem éri meg AI-al helyettesíteni, viszont nagyon hatékonyak a tudás elemzésében és az ember számára reflexszerűen végrehajtható mentális feladatokban, mint pl: a képfelismerés. Ez önmagában hatalmas automatizációs lehetőségeket hordoz! Úgy tekinthetünk az AI-ra mint egy ingyen és azonnal dolgozó, nagy tudású gyakornokra, korlátlan potenciállal. Az AI fejlesztők munkája ezt a potenciált a lehető legmagasabb szinten kihasználni és új képességeket, valamint ismereteket tanítani neki.
Az AI alkalmazása:
Mint azt már láttuk a nulláról tanítás rendkívül költséges folyamat, valamint minél több feladatra képes egy AI, minél több intelligensen megértett koncepcióval, annál könnyebben tud új ismereteket szerezni, mivel fel tud használni már meglévőket. Ez nem csak jobb eredményeket tesz lehetővé, hanem kevesebb adatból történő megértést is, mivel nem kell csak azokra korlátozva újra kiépíteni minden szükséges előismeretet, vagy képességet.
Egy AI annál jobb minél kevesebb adatból, minél gyorsabban, minél mélyebb és univerzálisabb összefüggéseket képes levonni, ez pedig nagyban hasonlít az IQ fogalmára.
Ahogyan az emberek esetén is, nem az újszülötteket próbáljuk programozásra tanítani, hanem a már iskolázottsággal rendelkező személyeket. Ugyanígy nem írunk új programozási nyelvet egy új projekt miatt.
Ha AI-t szeretnénk egy új feladatra, mindig jobb egy meglévőből kiindulni és azt tanítani, átalakítani!. Erre a nyílt (open source) fejlesztések a legjobbak, mert teljes hozzáférésünk van a hálóhoz, minden belső paraméterével, valamint nagyon sok szabványos, meglévő tool van a használatukra és integrációra.
A gyakorlatban ugyan fontos a hálók működésének ismerete, de minden szükséges számítást már megírtak több software library-ben. Ezek használata és a tanítandó adatok feldolgozása a legfontosabb!
Adatfeldolgozás:
Ahhoz, hogy egy neurális hálót alkalmazhassunk, meg kell tudnunk fogalmazni a tanulandó feladatot annak “nyelvén”. Digitális mivolta miatt számszerűsített, korlátozott tartományban lévő, fix számú és indexű be és kimenetekre kell átalakítani az adatokat, valamint ennek megfelelően kell megválasztani a háló struktúráját. Ez mindig az adott feladattól függ, pl: képfelismerésre a konvolúciós hálók a legjobbak, ahol a bemeneti neuronok a kép pixelei [0.0-1.0] tartományra normalizálva, a kimenet pedig az N felismerendő kategória. A tanítás alatt az ismert és kézzel annotált kép, adott kategóriához tartozó kimeneti neuronjának értéke 1.0 lesz, a többi 0.0. Meglévő háló esetén a létező kimenetek mellett fel tudunk vinni újakat is, amik új kategóriákat jelentenek. Az után tanítás (fine tuning) már nagyságrendekkel gazdaságosabb, mint tiszta lappal kezdeni.
Felhasználás új problémákra, tanítás nélkül:
A neurális háló alapvetően csak arra a problémára alkalmazható megbízhatóan, amire be lett tanítva (interpoláció), viszont valamennyire képes túllépni azon és aránylag közeli feladat területeken is működni (extrapoláció). Minél szélesebb körű képességekkel és ismeretekkel rendelkezik, annál messzebbre tud extrapolálni. Ez amúgy szintén nagyon fontos tényező az intelligencia szempontjából, mert a fejlődés, új tudás és képességek szerzése is inkrementális jellegű, sok apró iteratív lépés eredményeképp. Az AI hasonlóan működik itt is az emberi agyhoz.
Ezek miatt lehetőségünk van új feladatokra is felhasználni, hagyományos fine tuning tanítás nélkül! Ilyenkor nem módosítjuk a háló belső idegkapcsolat struktúráját, hanem a már meglévő ismereteire építünk, a bemeneti adatok okos megválasztásával!
Ezt többféleképpen megtehetjük:
Ha hasonló kategóriák között veszünk fel egy újat, akkor figyelhetjük a meglévő kategóriák aktiválását (pl: egy kamion esetén az “autó” és “konténer” kategóriákhoz rendelt kimeneti neuronok nagyobb, de nem teljes aktivitást mutatnak). Ugyanez igaz idősor, vagy trend analízisre: az ismert mintán kívüli kis tartományban még aránylag pontos eredményt kaphatunk.
Egy másik esetben egyszerűbb, már ismertebb alfeladatokra bontjuk le a problémát és ezen, elemi részekre futtatjuk le.
Ha a háló bemenete lehetővé tesz egyszerre több inputot (pl: hosszú szöveg), vagy rendelkezik rövid távú belső memóriával (rekurrens háló architektúra) akkor mutathatunk neki több, új, már megoldott referencia példát az új, megoldandó előtt, így nyújtva támaszt neki és növelve a hatékonyságát. A nagy nyelvi modellek (LLM) esetén ez egy bevált technika, ami a prompt engineering szakterületnek egy része.
AI futtatása és lehetőségek:
Az alap modellek tanításához sokszor szuper számítógépre van szükség, de a fine tuning már történhet erősebb személyi számítógépeken is. A futtatás (inference) viszont lehetséges akár ezektől jóval kisebb hardwaren.
A legnagyobb és legokosabb hálók futtatása persze masszív szervereket igényel és interneten át lehet csak elérni őket. Ezen széles határok között viszont sok olyan lehetőség akad, amely akár kis cégek, vagy egyének által is elérhető, tanítható és felhasználható!
Nagyon sok esetben olcsóbb, vagy nem kivitelezhető a cloud alapú AI, ilyenkor localban kell futtatni egy kisebb modellt (edge computing). Ilyen pl: a hálózattól távoli helyeken történő, felügyeletlen, vagy valós idejű döntéshozás, esetleg privát adatok kezelése.
Ebben a cikkben most idáig vizsgálódtunk, a következő írásban folytatjuk.
Summa-summárum…
A mesterséges intelligencia és a gépi tanulás mára mindenkinek elérhető eszközök. Nem csak forradalmasítják a technológiai világot, de megváltoztatják a hétköznapi életünket is, úgy, hogy szinte észre sem vesszük. Aki részt vesz ebben, az “láthatatlanul” is komolyabb piaci előnyt szerez. Ahogyan a technológia tovább fejlődik, az AI integrálása a szoftverekbe egyre inkább igény, sőt a versenyelőny fenntartásához abszolút kötelezővé válik. Az AI nem csak a jövőben, hanem már a jelenben is komoly szerepet játszik – következő blogbejegyzésünkben részletesen kifejtjük az AI alkalmazásainak néhány területét, és azok előnyeit. Lesz szó a nyelvi modellek egyedi alkalmazásáról, ezek közötti különbségekről, vektor adatbázisokról, langchain-ekről…stb.
Az Arteries csapata készen áll arra, hogy segítsen megérteni és bevezetni ezeket az új technológiákat, hogy ügyfeleink a legtöbbet hozhassák ki belőlük. Ha te is szeretnéd kihasználni az AI nyújtotta előnyöket, és megismernéd, hogyan alkalmazhatod a vállalkozásodban, vedd fel velünk a kapcsolatot!