Ezen cikkünkben az AI gyakorlati alkalmazásaiba fogunk elmélyülni. Főként a state of the art képfelismerő neurális hálózatokat fogjuk áttekinteni. Egy következő cikkünkben pedig kitérünk a nagy nyelvi modellekre is (LLM).
A képfelismerés vagy a szöveganalízis csak néhány példa arra, hogyan alkalmazható az AI a gyakorlatban. Az alábbi esetek szemléltetik, hogyan működnek ezek a technológiák a valós életben!
Mesterséges intelligencia alapú képfelismerés és képfeldolgozás
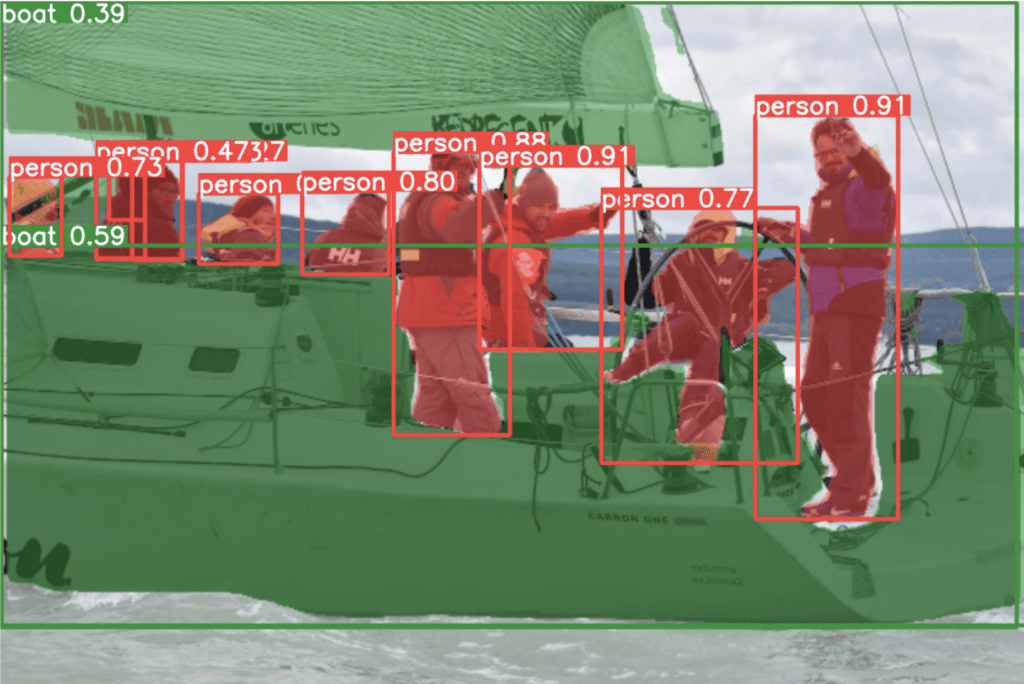
Ezen széleskörű terület magába foglalja a képek tartalmának ismert, előre meghatározott osztályokba sorolását (classification), adott objektumok képen való megtalálását (detection), vagy pixel pontos körbevágását (segmentation). Ezen kívül képesek még a kép tartalmának természetes nyelvű szöveges leírására, vagy akár univerzális, prompt alapú szabadszavas objektum keresésre! Nem csak detektálhatjuk a képeket, hanem a manapság erősen terjedőben lévő kép generátorokkal az emberi képzelet mintájára hozhatunk létre, vagy módosíthatunk képeket!
Léteznek módszerek 3D rekonstrukcióra több látószög alapján, vagy akár monokuláris (1 db) képéből ki következtetve. Több kamera képét egyszerre összekombinálva olcsó 3D scanner-é alakíthatjuk őket! Erre a legjobb megoldás a NeRF (Neural Radiance Fields), de sztereoszkopikus (szem mintájára egymás mellett lévő) kamerák képéből is jól számítható távolság.
A képfelismerés rendkívül sok módon használható, intelligens kamerákat készíthetünk, amik nem csak néznek, hanem látnak! Nem csak felismerni képesek az objektumokat, de értékelni is tudják, pl: épp, vagy sérült e egy termék; milyen autó van a képen; hány személy, vagy ki látható rajta…
A neurális képfeldolgozás terület egyik legnagyobb előnye a számítási kapacitás igénye: megfelelő tudás birtokában szinte bármilyen számítógépen, vagy akár mobil telefonon is helyben, offline használhatóak, valamint moderált számítási kapacitással taníthatóak be új kategóriák felismerésére!
Alább a nyílt forráskódú, szabadon elérhető és egyben csúcs teljesítményt nyújtó, “state of the art” neurális hálózatokat mutatjuk be:
Objektum detekció és szegmentáció, You Only Look Once (YOLO) v8-al